
Propagation of Uncertainty
Author: J. M. McCormick
Last Update: August 27, 2010
Introduction
Every measurement that we make in the laboratory has some degree of uncertainty associated with it simply because no measuring device is perfect. If a desired quantity can be found directly from a single measurement, then the uncertainty in the quantity is completely determined by the precision of the measurement. It is not so simple, however, when a quantity must be calculated from two or more measurements, each with their own uncertainty. In this case the precision of the final result depends on the uncertainties in each of the measurements that went into calculating it. In other words, uncertainty is always present and a measurement’s uncertainty is always carried through all calculations that use it.
Fundamental Equations
One might think that all we need to do is perform the calculation at the extreme of each variable’s confidence interval, and the result reflecting the uncertainty in the calculated quantity. Although this works in some instances, it usually fails, because we need to account for the distribution of possible values in all of the measured variables and how that affects the distribution of values in the calculated quantity. Although this seems like a daunting task, the problem is solvable, and it has been solved, but the proof will not be given here. The result is a general equation for the propagation of uncertainty that is given as Eqn. 1.2 In Eqn. 1 f is a function in several variables, xi, each with their own uncertainty,Δxi.
|
|
(1) |
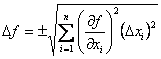
From Eqn. 1, it is possible to calculate the uncertainty in the function, Δf, if we know the uncertainties in each variable and the functional form of f (so we can calculate the partial derivatives with respect to each variable). It is easier to understand how this all works by doing several examples.
Example 1: f = x + y (the result is the same for f = x – y).
Let the uncertainty in x and y be Δx and Δy, respectively. Taking the partial derivatives with respect to each variable gives: ![]() and
and ![]() . The uncertainty in f is then
. The uncertainty in f is then ![]() , or
, or
|
|
(2) |
Example 2: f = x•y (also works for f = x/y)
Again let the uncertainty in x and y again be Δx and Δy, respectively. Taking the partial derivatives with respect to each variable gives: ![]() and
and ![]() . The uncertainty in f is then
. The uncertainty in f is then ![]() .
.
This result is more commonly written by dividing both sides by f = x•y to give
|
|
(3) |
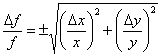
Although the idea of error propagation may seem intimidating, you have already been using it since your first chemistry class when you applied the rules for significant figures in calculations. These rules are simplified versions of Eqn. 2 and Eqn. 3, assuming that Δx and Δy are both 1 in the last decimal place quoted. The formal mathematical proof of this is well beyond this short introduction, but two examples may convince you.
If we add 15.11 and 0.021, the answer is 15.13 according to the rules of significant figures. This assumed that Δx = 0.01 (x = 15.11) and Δy = 0.001 (y = 0.021), substituting these values into Eqn. 2, we get![]() . Remembering our basic statistics, we know that the uncertainty begins in the first non-zero decimal place, which in this case this means that the last significant figure in the sum is the 1/100thsplace. According to the rules for propagation of error the result of our calculation is 15.13 ± 0.01, exactly what the significant figure rules gave us.
. Remembering our basic statistics, we know that the uncertainty begins in the first non-zero decimal place, which in this case this means that the last significant figure in the sum is the 1/100thsplace. According to the rules for propagation of error the result of our calculation is 15.13 ± 0.01, exactly what the significant figure rules gave us.
If we had multiplied the numbers together, instead of adding them, our result would have been 0.32 according to the rules of significant figures. Again assuming Δx = 0.01 and Δy = 0.001, and using Eqn. 3, we can determine Δf as follows.
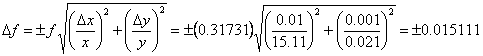
Once again we see that the uncertainty begins in the second decimal place, which gives the same result as the significant figures result gave.
The significant figure rules are important to know and use in all chemistry calculations, but they are limited in that they assume an uncertainty in the measured quantities. So while the significant figure rules are always to be used in any calculation, when precision matters a propagation of error analysis must also be performed to obtain an accurate prediction of the uncertainty arising from the precision of the measured quantities.
Worked Examples
Problem 1
In CHEM 130, you have measured the dimensions of a copper block (assumed to be a regular rectangular box) and calculated the box’s volume from the dimensions. In that exercise you were given an equation that allowed you to calculate the minimum uncertainty that could be expected in the box’s volume based solely on the uncertainties in the measured dimensions, now derive that equation using the procedure given above.
Solution
Let x, y and z be the box’s length, width and height, respectively, and the uncertainties be Δx, Δy, Δz. Since V = x·y·z, we can use Eqn. 1 to determine the uncertainty in the volume (ΔV), which results in Eqn. 4. We know that ![]() ,
, ![]() and
and ![]() , and can then make these substitutions in Eqn. 4 to give Eqn. 5.
, and can then make these substitutions in Eqn. 4 to give Eqn. 5.
|
|
(4) |
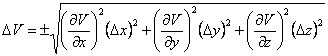
|
|
(5) |
Dividing both sides by V gives Eqn. 6 and simplifying gives Eqn. 7 (which you probably could have guessed from the form of Eqn. 1 and Eqn. 3). Multiplying both sides by V then gives the equation used in the CHEM 120 Determination of Density exercise.
|
|
(6) |
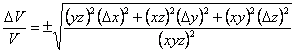
|
|
(7) |
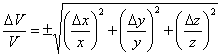
Note that there are several implications of Eqn. 7. First, if one side has a large uncertainty relative to the length of that side (such as when one side is very short), then this side will dominate the uncertainty. Second, when the volume is large and the uncertainty in measuring a dimension is small compared to the uncertainty in the measurement, then the uncertainty in the volume will be small. The experimental implication of this is that, if you want the smallest uncertainty in a box’s volume, make sure it is a big box, with no unusually short side and use the most precise measurement tool possible.
Problem 2
You have measured the volume and mass of a set of regular wooden blocks and have fit a graph of their volume as a function of their mass to a straight line using the regression package in Excel. What is the predicted uncertainty in the density of the wood (Δd) given the uncertainty in the slope, s, of the best fit line is Δs and the uncertainty in the intercept is Δb? Note that you have also seen this equation before in the CHEM 120 Determination of Density exercise, but now you can derive it.
Solution
The relationship between volume and mass is ![]() . This is a linear equation (y = s•x + b) where
. This is a linear equation (y = s•x + b) where ![]() . Note that b does not affect
. Note that b does not affect
the value of d and so Δb has no effect on Δd. The relationship between Δs and Δd can be calculated by simply substituting d in place of f and s in place of x in Eqn. 3 to give 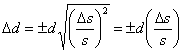 .
.
We could have also have used Eqn. 1. First we need to find the first derivative of the density with respect to the slope, which is ![]() Substituting this into Eqn. 1 gives
Substituting this into Eqn. 1 gives 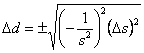 , which rearranges to
, which rearranges to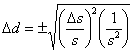 . Recognizing the relationship between s and d, this simplifies to
. Recognizing the relationship between s and d, this simplifies to ![]() .
.
This problem is the simplest example of how one determines the uncertainty in a quantity extracted from a best-fit line. In general you will have the uncertainty in the slope and intercept and the relationship between each of these to the desired quantities. It is then a simple process to apply Eqn. 1, where f is either the slope or intercept.
Propagation of Uncertainty through a Calibration Curve
A situation that is often encountered in chemistry is the use of a calibration curve to determine a value of some quantity from another, measured quantity. For example, in CHEM 120 you created and used a calibration curve to determine the percent by mass of aluminum in alum. In that exercise, we did not propagate the uncertainty associated with the absorbance measurement through the calibration curve to the percent by mass. However, in most quantitative measurements, it is necessary to propagate the uncertainty in a measured value through a calibration curve to the final value being sought. The general procedure is quite straight-forward, and is covered in detail in CHEM 222. Therefore, only a very basic review of the fundamental equations and how to implement them in Excel will be presented here. You are referred to any analytical chemistry textbook for more details.3
For a linear least squares analysis we need to define several parameters. We will assume that the equation of a straight line takes the form y = mx + b (where m is the slope and b the intercept) and that the x values are known precisely. Let there be N individual data points (so there are N ordered pairs xi, yi) in the calibration curve. Further, let ymeas be the average response of our unknown sample based on M replicate measurements, and let Smeas be the standard deviation of the result from the calibration curve. Note that Smeas is the standard deviation associated with the x value (xmeas) corresponding to ymeas, and should not be confused with Sr, the standard deviation about the regression. We can then draw up the following table to summarize the equations that we need to calculate the parameters that we are most interested in (xmeas and Smeas).
| Equation | Location on Regression Output Worksheet | Excel Command |
|---|---|---|
| ------------- | DEVSQ(arg) | |
| Under the ANOVA heading it is the entry in the row labeled "Total" in the "SS" column. | DEVSQ(arg) | |
| ------------- | ------------- | |
| ------------- | AVERAGE(arg) | |
| ------------- | AVERAGE(arg) | |
| Coefficient listed under "X Variable 1". | SLOPE(known y's, known x's) | |
| INTERCEPT(known y's, known x's) | ||
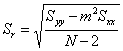 | STEYX(known y's, known x's) | |
| ------------- | ------------- | |
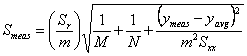 | ------------- | See below. |
Table 1. Relationships between standard equations encountered in a linear least squares analysis and the Excel regression package output and Excel commands. Note that arg in the Excel command refers to a range of cells over which the command is to be calculated (e. g., E5:E10).
Although one could enter formulas in various cells to calculate all of the intermediate parameters needed to determineSmeas, it is not necessary. One only needs to have a cell in which to enter the number of replicate measurements on the unknown (M) and then it is possible to calculate Smeas using only the STEYX, SLOPE, INTERCEPT, COUNT, DEVSQ and SQRT Excel functions. For example, in the spreadsheet shown in Fig. 1, cell D16 contains the formula
“=(STEYX(D3:D13,C3:C13)/SLOPE(D3:D13,C3:C13))*SQRT((1/D15)+(1/COUNT(D3:D13))+((D18-AVERAGE(D2:D13))^2/(SLOPE(D3:D13,C3:C13)^2*DEVSQ(C2:C13))))”
which calculates Smeas directly from the potential as a function of temperature data. Adding a cell that will contain ymeas(cell D17 in Fig. 1), allows calculation of xmeas value (cell D18) and its uncertainty at 95% confidence (cell D19). Click here to review how this is done using Smeas and Student’s t. Note that instead of using N in the calculation of the uncertainty from Smeas, one must use N-2 because two degrees of freedom have been used to find the slope and the intercept.
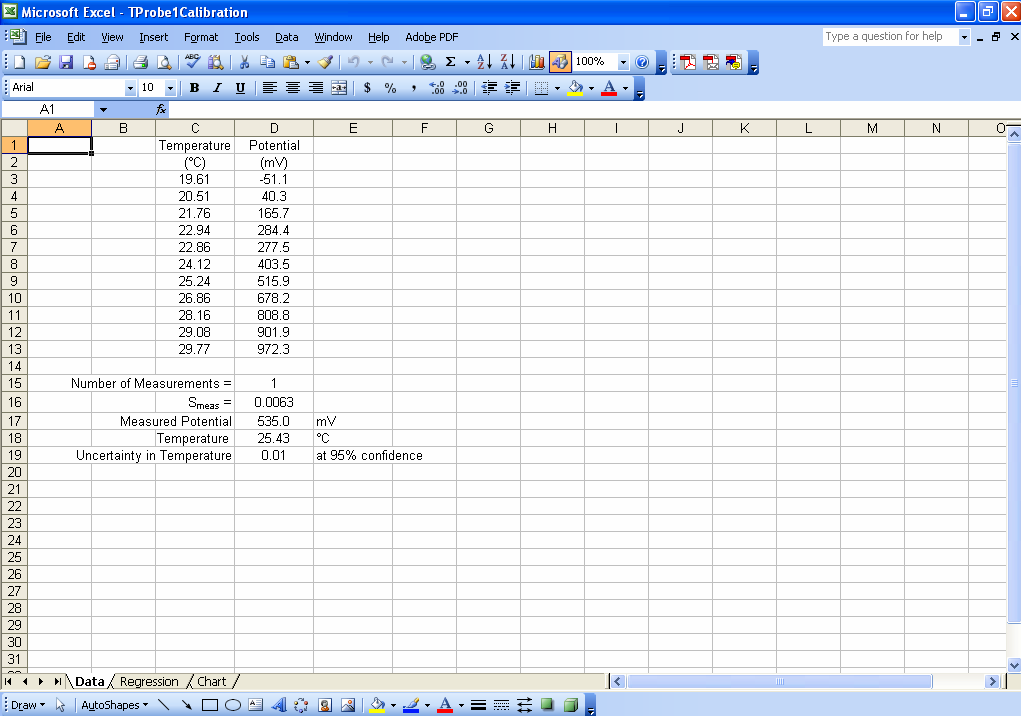
Figure 1. An example of an Excel spreadsheet that may be used to calculate an x value (temperature, in this case) from a measured y value (potential) along with the uncertainty in the measured x value at 95% confidence.
Propagation of Uncertainty of Two Lines to their Intersection
Sometimes it is necessary to determine the uncertainty in the intersection of two lines. This problem is not trivial and the reader is referred to the literature for more details.4
References
1. Click here to obtain this file in PDF format (link not yet active).
2. Andraos, J. J. Chem. Educ. 1996, 73, 150-154. Click here to view this article on the Journal of Chemical Education web page (Truman addresses and J. Chem. Educ. subscribers only).
3. Skoog, D. A.; West, D. M. and Holler, F. J. Fundamentals of Analytical Chemistry, 5th Ed.; Saunders College Publishing: New York, 1988; p. 39-42.
4. Carter Jr., K. N.; Scott; D. M.; Salmon, J. K. and Zarcone, G. S. Anal. Chem. 1991, 63, 1270-1270. Click here to view this article in PDF format on the Analytical Chemistry web page (Truman addresses and Analytical Chemistry subscribers only).